Weed Detection: A Fine-Grained Classification Problem [IN PROGRESS]
Note: This project is still active and will be updated as progress is made. Please feel free to email me at yuelinnchong@gmail.com for further information or if you have any questions regarding the work presented. Thank you for your patience and interest.
Abstract
The following work is a preliminary study on fine-grained classification with the use case of weed detection. State-of-the-art methods in image detection and current methods used in weed identification are presented. Weed detection datasets are also listed. From existing methods and datasets, a baseline for weed identification using Faster-RCNN on the Open Plant Phenotyping Dataset (OPPD) is proposed. Preliminary experiments to evaluate this baseline is presented. Based on these experiments, future improvements for weed detection in the wild is suggested.
1. Introduction
Accurately ascertaining the efficacy of weeding methods is critical for optimising agricultural processes. Automating the evaluation of weeding methods would eliminate human error and labour costs, making the process reliable and scalable.
A basic capability required to autonomously evaluate weeding methods is to locate all the weeds present in a given area. Additionally, it may be necessary to identify the species of the weeds as the efficacy of weeding methods may vary for different weed types.
Therefore, this work will focus on weed detection which includes the localisation of weeds as well as the identification of the species of the located weeds.
The remaining sections are structured as follows:
- Existing methods in image detection and fine-grained classification are discussed in Section 2.
- Datasets relevant to weed detection is presented in Section 3.
- A baseline method based on existing methods and available datasets is proposed in Section 4. Results of preliminary experiments for the proposed baseline are also discussed in Section 4.
- Potential challenges and alternative approaches are explored in Section 5.
2. Related Works
Image detection is used to locate and classify objects in an image. Image detection methods can generally be divided into two types based on the way objects are marked: the objects are either bounded with a box or each pixel of the object is classified. Bounding box methods include YOLOv4, CenterNet2, and Faster R-CNN. Methods that classify each pixel, also known as instance or semantic segmentation, include Mask R-CNN, SegNet, and U-Net.
Generally, image detection methods are used for classifying objects that look dissimilar to each other (eg. a dog vs a human). In contrast, identifying weeds is more challenging as crops and weeds have similar appearances. Weeds from different species may also appear similar to each other, especially in earlier growth stages.
Thus, weed detection fall within the paradigm of fine-grained detection where objects of different classes largely share similar features.
Fine-grained detection methods such as TransFG and MMAL-Net have been used for classification for aircraft, cars, dogs, or birds. Image detection methods have also been fine-tuned to perform fine-grained detection.
Methods presented specifically for weed detection have been presented in A Survey of Deep Learning Techniques for Weed Detection from Images, Advanced Machine Learning in Point Spectroscopy, RGB- and Hyperspectral-Imaging for Automatic Discriminations of Crops and Weeds: A Review, and Weed Detection for Selective Spraying: A Review.
3. Dataset
Annotated datasets are required to test and train the weed detection methods. Several datasets on weed detection are publically available, some of which are shown in the table below.
| Dataset Name | Type | Size |
|---|---|---|
| Sugar Beets 2016 (Crop-Weed for Semantic Segmentation) [Paper] | 4-channel multi-spectral camera and a RGB-D images | 12,340 labeled images, 5TB |
| Weed Recognization (2018) [Report] | Multi-resolution Aerial tiles | 38 images (45,600 patches) |
| V2 Plant Seedlings Dataset (Kaggle) | RGB images | 5,539 images of crop and weed seedlings |
| Carrot-Weed [Paper] | RGB images | 39 labelled images |
| A Crop/Weed Field Image Dataset [Paper] | RGB images | only 60 images, annotated |
| Dataset of annotated food crops and weed images for robotic computer vision control [Paper] | RBG images | 1,118 images |
| Combing K-means Clustering and Local Weighted Maximum Discriminant Projections for Weed Species Recognition [Paper] | RGB images | “Eight kinds of 1,600 weed images per plant” |
| Deepweeds | RGB images | 17,509 labelled images |
| GrassClover Dataset [Paper] | RGB images (synthetic) | 31,600 unlabeled images |
| Open Plant Phenotyping Dataset [Paper] | RGB images | 7,590 RGB images of 47 plant species, 3 different growth conditions |
4. Proposed Baseline
OPPD was chosen as it had the most variety of weeds available with full images. However, OPPD only provides bounding box labels. Thus, the baseline method is limited to bounding box type detectors. As such, Faster-RCNN was chosen as a baseline for weed detection in this work. This is primarily because of the pervasive use of Faster-RCNN in weed detection literature. However, there is the intention to compare this baseline with other detection methods listed in Section 2 using OPPD.
Due to computing limitations, some modifications were made for the following preliminary experiments to obtain the baseline’s performance. Most notably, the smaller VGG16 was used as a feature extractor in Faster-RCNN due to limited RAM capacity. The experiments were also based on an unofficial implementation of Faster-RCNN as there were no GPU resources available. Currently, only two weed species were extracted from OPPD for training and evaluation. However, as the project progresses, more species will be added in. The two species of weeds extracted are CHEAL (Fat-hen) and EPHHE (Umbrella milkweed), which had the most images in the dataset.
The Faster R-CNN network was partially trained with data from OPPD (the weights in the VGG16 layers were fixed). With only 2 weed species used for training, a total of 417 images were used to fine-tune the pre-train weights of Faster-RCNN. On a laptop with i5-6300U CPU @ 2.40GHz, each training iteration takes about 16 seconds with a batch size of 1. Currently, the best model was trained for 3,258 iterations and the following results presented are based on this model.
An example of the detections using train data is shown in Figure 1. The model was then tested on images obtained online by searching for ‘Fat-hen’ and relevant images were selected shown in Figure 2 and 3. Figure 4 shows the model tested on data from the OPPD dataset but for a different weed species.
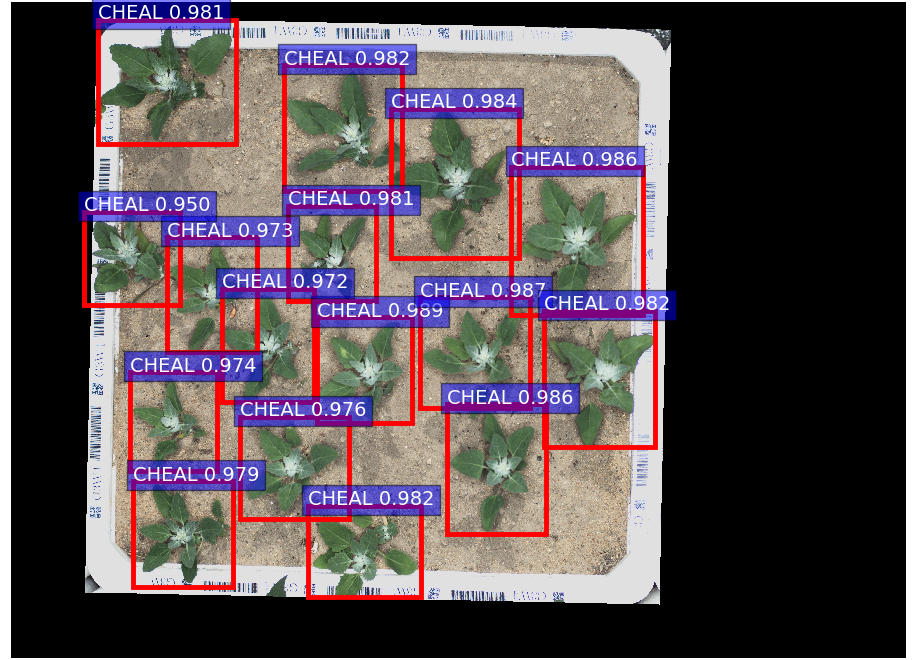
Figure 1. Detections for an image from the train set.

Figure 2. Detections for an image from the internet which has similar appearance to that of training data.

Figure 3. Detections for an image from the internet with larger Fat-hen weeds.

Figure 4. Detections for an image from the same dataset but of a different species of weed not seen during training.
As expected, the model is able to detect weeds in conditions similar to that of the training data as shown in Figure 2. Although, the model is still not perfect and missed out on some plants. The model is also not able to generalise to the plants at later growth stages as shown in Figure 3, despite the similarity in visual cues such as the leaf shape. More notably, the model had fairly confidently marked a different species of weed with a very different appearance as a known species as shown in Figure 4. This result is expected as there were no special mechanisms to capture features of new plants implemented yet.
Implementation of this work is made available at https://github.com/yuelinn/tf-faster-rcnn-cpu.
Do note that these results are still preliminary and the proper procedure for quantifying the performance of the model is still underway.
5. Future Work
To deploy weed detection for real-world applications, the method has to be able to detect previously unseen weeds. There is a high probability that the weeds seen in the wild are not found in any labelled dataset as the number of weeds available in the dataset is limited. Dataset annotation requires manual labour; the annotation process is slow and expensive. Hence, it is not realistic to label sufficient data for all the weeds in the world.
Instead, the method has to be able to identify weeds that were not previously labelled and change its model to include the new weed automatically. As illustrated in the previous section, current methods used in image detection is not capable of classifying new plants without modifications. To correctly identify new weeds, it is possible to leverage similarities between weed species. As weed species can be represented as a network rather than discrete classes, unsupervised methods paired with Graph Neural Networks could be used for classifying new weeds.
Typically deep learning methods generalise better by learning with more data in a supervised fashion. However, as previously mentioned, data is expensive to label. Hence, active learning methods are deployed to reduce the amount of labelling required while improving the performance of the model. Given that plants do not move, it is possible to perform automatic labelling in addition to active learning to further reduce the number of manual annotation required.
Ideally, the model should be able to learn with minimal or no labelled data. From the internet and during deployment in the field, camera images of weeds are fairly available. Semi-supervised methods can be used so that the model learns from these unlabelled data; typically by assisting the model to better map the inputs to a higher feature space.